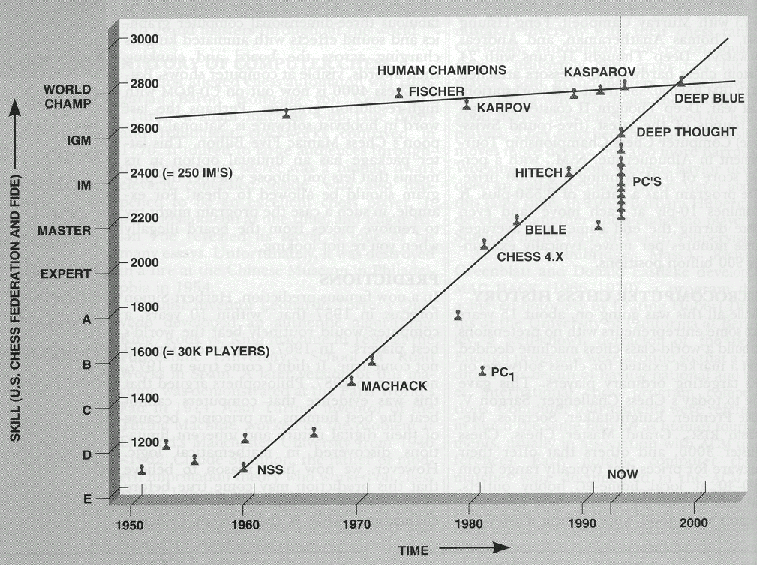
Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Descrição

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional

How did Google's AlphaZero beat the world's best chess computer?

The future is here – AlphaZero learns chess
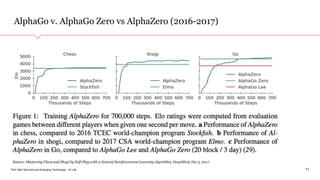
Gamifying Strategy - Enterprise AI use cases on agent-based simulation and reinforcement learning
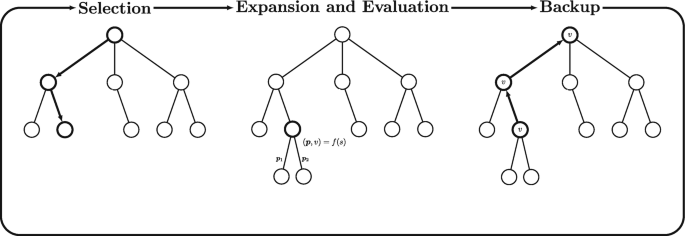
Planning with a Model: AlphaZero

PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
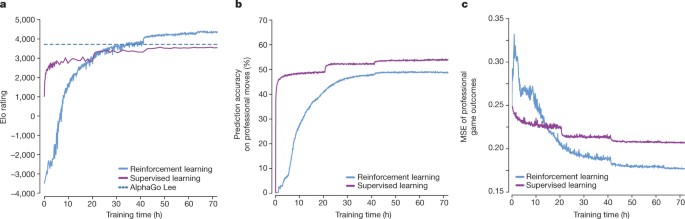
Mastering the game of Go without human knowledge
How many games did Alpha Zero played against itself during its four hours training? - Quora
de
por adulto (o preço varia de acordo com o tamanho do grupo)