Mastering chess and shogi by self-play with a general
Por um escritor misterioso
Descrição

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AlphaZero's 'alien' superhuman-level program masters chess in 24 hours with no domain knowledge « the Kurzweil Library + collections

Mastering Atari, Go, chess and shogi by planning with a learned model

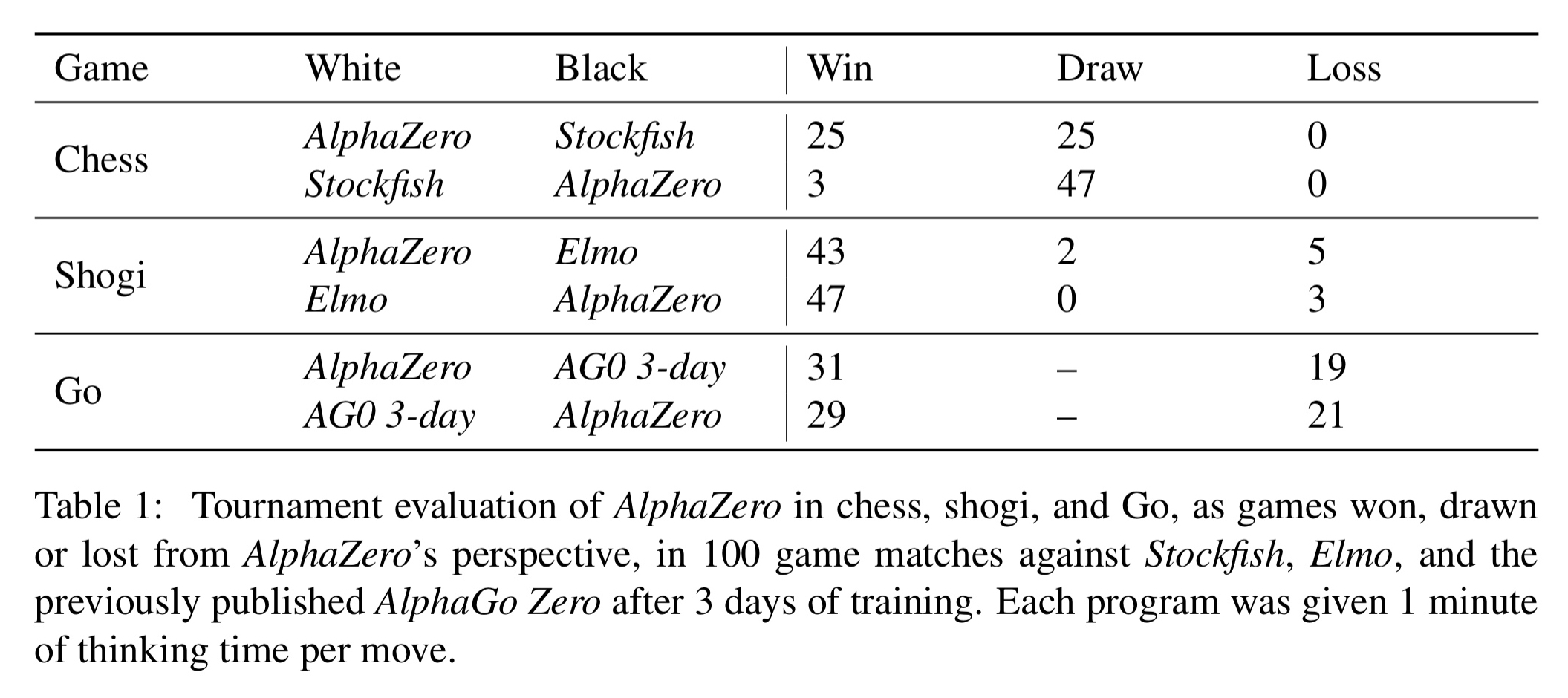
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
R] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm : r/MachineLearning
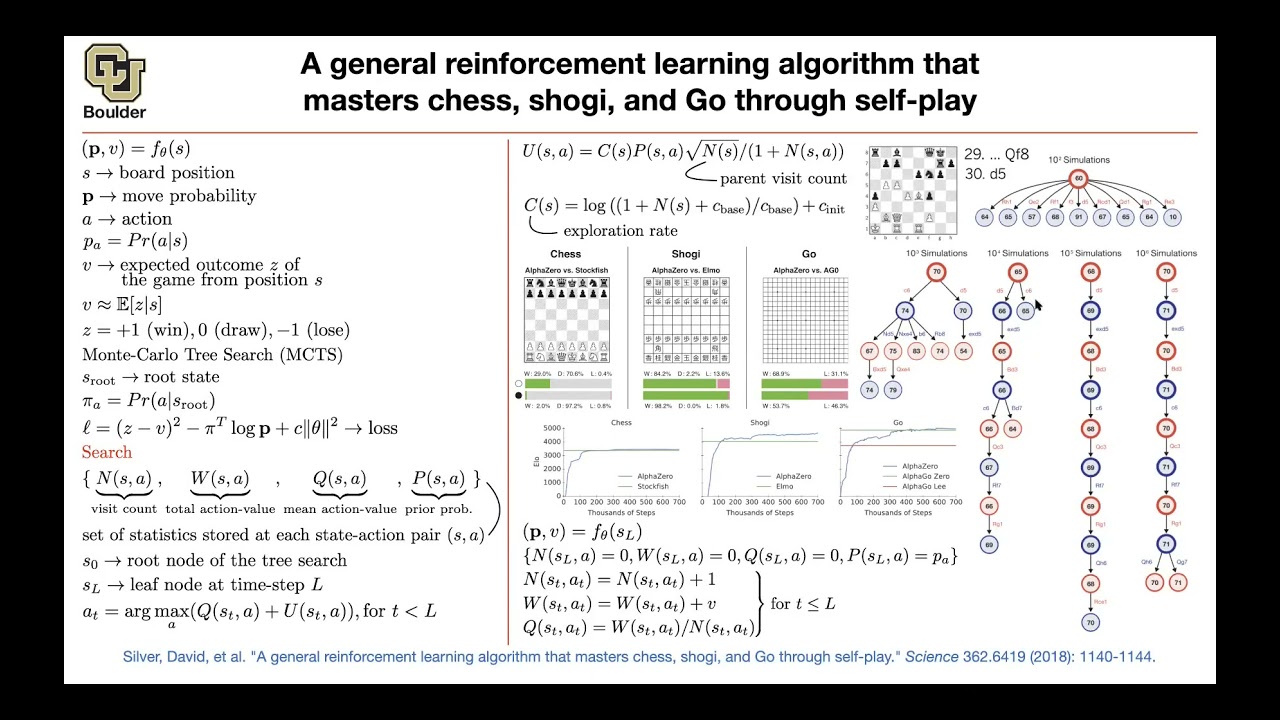
AlphaZero, Lecture 82 (Part 2)
Mastering chess and shogi by self-play with a general reinforcement learning algorithm

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
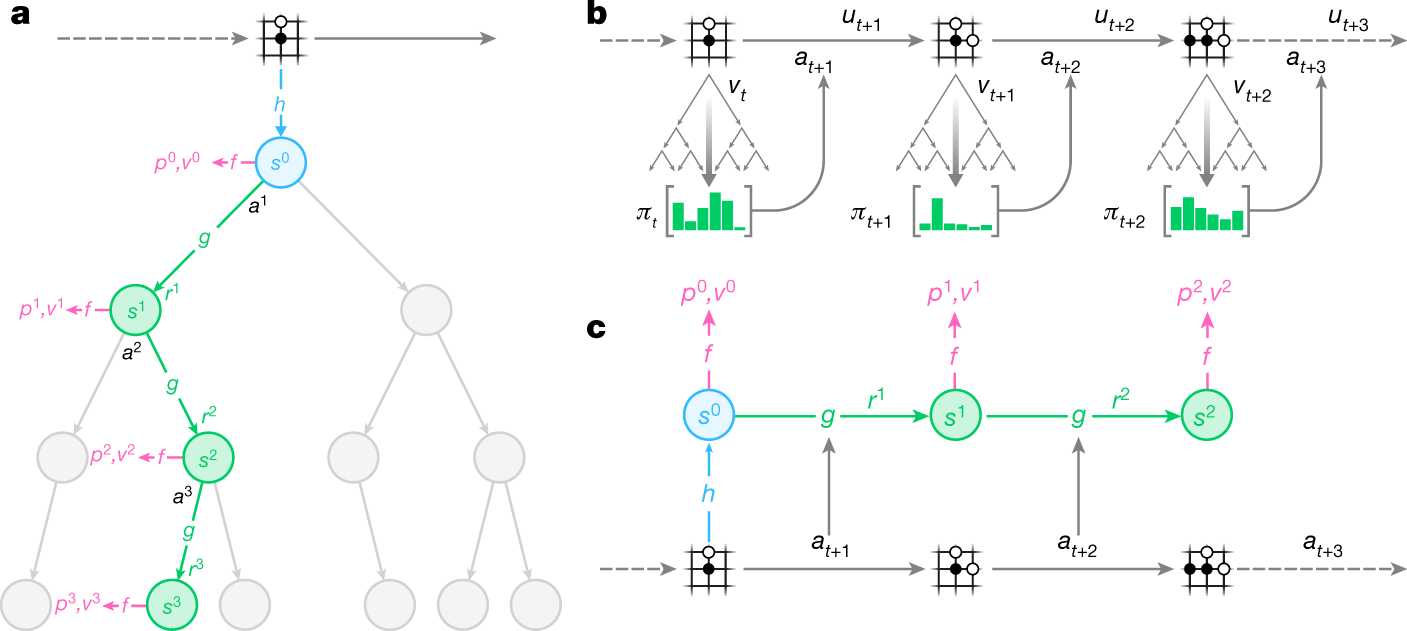
Mastering Atari, Go, chess and shogi by planning with a learned model

Mastering chess and shogi by self-play with a general reinforcement learning algorithm

PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

AlphaZero AI beats champion chess program after teaching itself in four hours, DeepMind
de
por adulto (o preço varia de acordo com o tamanho do grupo)